
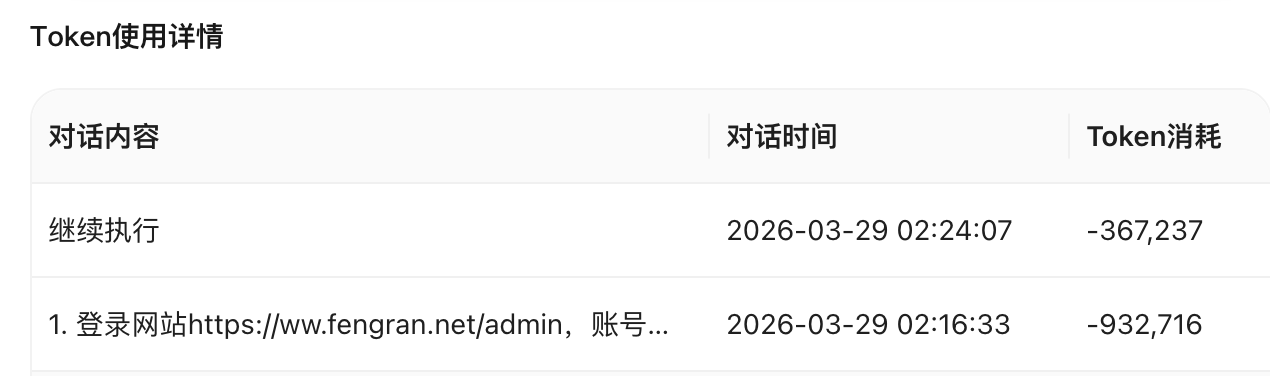
 燃点博客
燃点博客 这篇文章是使用 openclaw 自动抓取二创,发布的,消耗了挺多 tokens
引言:AI开发的新纪元
2025年3月18日,在GTC全球开发者大会上,英伟达(NVIDIA)发布了一款革命性的产品——DGX Spark个人AI超级计算机。这款被黄仁勋称为"全球最小AI超级计算机"的设备,以其惊人的性能密度和紧凑设计,彻底改变了AI开发的格局。它将数据中心级的算力带入桌面环境,让开发者、研究人员和学生都能在本地完成大型AI模型的开发、微调和推理工作。
DGX Spark的发布标志着AI技术普惠化的重要里程碑。过去,开发和训练大型AI模型需要昂贵的数据中心设备,只有大型科技公司才能负担。而现在,随着DGX Spark的问世,个人开发者也能拥有一台真正的AI超级计算机,在自己的办公桌上完成前沿AI模型的研发工作。
一、产品定位与技术架构
1.1 核心设计理念
英伟达DGX Spark的核心设计理念是"让AI开发从云端延伸到本地"。通过紧凑的硬件形态和全栈软件支持,它满足了开发者、研究人员及学生在本地对大型AI模型进行原型设计、微调和推理的需求。这一理念体现了英伟达对AI民主化的坚定承诺。
1.2 Grace Blackwell超级芯片
DGX Spark搭载的GB10 Grace Blackwell超级芯片是其核心亮点。这款芯片整合了Blackwell架构GPU与ARM架构CPU,采用第五代Tensor Core和FP4精度支持,每秒可执行高达1,000万亿次运算(TOPS),专为生成式AI、物理AI和机器人基础模型的推理优化。

GB10芯片中的GPU部分拥有6144个CUDA核心,规模与RTX 5070桌面显卡核心数量完全一致。这一配置让DGX Spark能够胜任复杂的AI计算任务,同时保持较低的功耗水平。
1.3 NVLink-C2C互连技术
通过CPU与GPU内存一致性模型,NVLink-C2C技术实现了900GB/s的超高带宽,达到第五代PCIe的5倍。这一突破性技术显著优化了内存密集型任务(如大模型参数加载)的效率,让数据在CPU和GPU之间无缝流动。
二、硬件规格详解
2.1 紧凑设计与核心配置
DGX Spark以"全球最小AI超级计算机"为设计目标,其体积仅150×150×50.5mm,重量约1.2kg,功耗仅170W,投影面积甚至比iPad mini还小。但在这小巧的机身内,却蕴含着惊人的计算能力:
- CPU:20核ARM处理器(10个Cortex-X925超大核 + 10个Cortex-A725高性能核)
- GPU:Blackwell架构,集成第五代Tensor Core与第四代RT Core
- 内存:128GB LPDDR5x统一内存,256位总线,带宽高达273GB/s
- 存储:M.2 PCIe NVMe插槽(可选1TB/4TB SSD)
- 连接性:Wi-Fi 7、蓝牙5.3、10GbE ConnectX-7智能网卡
- 接口:4×USB4(40Gbps)、1×HDMI 2.1、1×10Gbps RJ45、2×200Gbps QSFP
2.2 性能表现
DGX Spark可提供单机运行2000亿参数模型的能力,双机互联更可扩展至4050亿参数。单机拥有1 PFLOP的FP4稀疏AI算力,支持200B参数模型本地推理和70B参数模型本地微调。

三、2026年重大更新:集群功能
2026年3月,NVIDIA为DGX Spark平台推出了全新的集群功能,进一步强化了该平台在企业团队开发和部署自主AI智能体领域的核心地位。
3.1 多节点集群架构
根据GTC 2026大会公布的更新,DGX Spark现在能够以统一的配置,将最多四个系统无缝集群连接。这意味着企业无需改造现有的IT机房,直接在工程师的办公桌边,就能构建出一个拥有极高算力密度的紧凑型"桌面数据中心"。
四台DGX Spark并行后具备:
- 4 PFLOPS算力(4千万亿次/秒)
- 512GB统一内存
3.2 多种运行拓扑结构
DGX Spark支持多种运行拓扑结构,都依托ConnectX-7网卡提供的低延迟RoCE通信:
| 拓扑结构 | 适用场景 | 性能指标 |
|---|---|---|
| 单节点 | 低延迟、大上下文长度推理 | 推理200B参数模型、微调120B参数模型 |
| 双节点 | 均衡扩展,更快微调 | 推理400B参数模型 |
| 三节点(环形) | 更大模型微调或小型训练 | 适合中等规模训练任务 |
| 四节点(RoCE交换机) | 本地推理服务器、AI工厂 | 推理700B参数前沿大模型 |
四、软件生态与全栈支持
4.1 DGX OS操作系统
DGX Spark运行NVIDIA自主研发的DGX OS操作系统,这是一款基于Linux的定制系统,预装了完整的NVIDIA AI软件堆栈。用户开箱即用,无需复杂的配置即可开始AI开发工作。
4.2 NVIDIA AI软件栈
系统集成了:
- CUDA-X AI平台:提供全面的AI开发工具
- NIM微服务:简化模型部署流程
- NeMo框架:支持大规模模型训练和推理
- TensorRT:优化推理性能
4.3 NemoClaw开源软件栈
2026年,NVIDIA同步推出了全新的NemoClaw开源软件栈,与DGX Spark形成完整的全栈式平台。开发者可以在本地构建并运行需要持续工作的自主AI智能体,完成早期的原型设计与验证,随后再平滑扩展到大型"AI工厂"或数据中心基础设施中。
五、应用场景与用户群体
5.1 目标用户
DGX Spark专为以下用户群体设计:
- AI开发者:在本地快速原型设计和测试模型
- 研究人员:进行前沿AI算法研究
- 数据科学家:处理大规模数据分析和建模
- 学生和教育机构:学习AI技术,进行教学实践
- 初创企业:低成本获取高性能AI算力
5.2 典型应用场景
- 大语言模型开发:本地微调和部署200B参数级别的大模型
- 多模态AI:处理文本、图像、音频等多模态数据
- 机器人AI:开发和测试机器人基础模型
- 科学计算:物理模拟、生物信息学等计算密集型任务
- 自主AI智能体:构建和部署持续运行的AI助手

六、价格与供货
DGX Spark提供多个版本:
- 标准版:售价3,000美元起(约21,691元人民币)
- FE版本(4TB存储):售价3,999美元(约28,533元人民币)
- 两台套装(含连接线):售价8,049美元
除NVIDIA官方版本外,合作伙伴宏碁、华硕、戴尔、技嘉、惠普、联想、微星也将推出基于GB10芯片的"非公"系统,为用户提供更多选择。
七、与DGX Station的对比
英伟达同时推出了更高端的DGX Station,两者定位不同:
| 特性 | DGX Spark | DGX Station |
|---|---|---|
| 芯片 | GB10 Grace Blackwell | GB300 Blackwell Ultra |
| AI算力 | 1 PFLOPS | 20 PFLOPS |
| 内存 | 128GB | 784GB |
| 功耗 | 170W | 更高 |
| 定位 | 个人/小型团队 | 企业级AI工作站 |
八、行业影响与未来展望
8.1 推动AI民主化
DGX Spark的发布是AI民主化进程中的重要一步。它让更多的个人开发者、学生和小型团队能够接触和使用高性能AI计算资源,这将激发更多的创新和突破。过去只能在大型科技公司内部进行的AI研发工作,现在可以在任何人的办公桌上完成。
8.2 重塑AI开发流程
传统AI开发流程需要依赖云端资源,不仅成本高昂,而且存在数据安全和隐私问题。DGX Spark让开发者能够在本地完成模型的原型设计、微调和测试,然后再根据需要部署到云端或数据中心,实现了开发流程的灵活性和高效性。
8.3 未来发展
随着AI技术的快速发展,对计算资源的需求将持续增长。英伟达通过DGX Spark展示了其在AI硬件领域的领先地位,同时也为未来的产品创新指明了方向。我们可以期待更多性能更强、功能更丰富的个人AI超级计算机产品出现。
结语
英伟达DGX Spark不仅是一款硬件产品,更是AI时代的里程碑。它以小巧的机身承载了巨大的计算能力,将数据中心级的AI算力带到了每一位开发者的桌面。无论是对于个人开发者还是企业用户,DGX Spark都提供了一个前所未有的选择:在本地拥有真正的AI超级计算机。
随着2026年集群功能的加入,DGX Spark的能力得到了进一步扩展,从个人开发工具升级为可支撑企业级AI应用的基础设施。对于希望进入AI领域的开发者来说,DGX Spark无疑是一个值得考虑的选择。
关于作者:本文综合整理自NVIDIA官方发布、GTC大会演示及多家科技媒体报道。
本文发布于2026年03月29日02:18,已经过了112天,若内容或图片失效,请留言反馈 转载请注明出处: 燃点博客
本文的链接地址: https://ww.fengran.net/好文转载/44.html
-

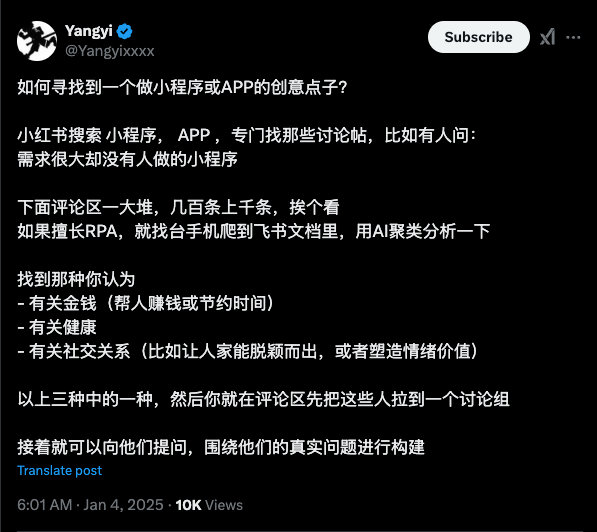
如何寻找到一个做小程序或APP的创意点子?
来源:x.com/Yangyixxxx/status/1875512836442746883 小红书搜索 小程序, APP ,专门找那些讨论帖,比如有人问: 需求很大却没有人做的小程序 下面评论区一大堆,几百条上千条,挨个看 如果擅长RPA,就找台手机爬到飞书文档里,用AI聚类分析一下 找到那种你认为 有关金钱(帮人赚钱或节约时间) 有关健康 有关社交关系(...
2025/01/05
-
每天都有 AI 产品"炸裂",但我已经不焦虑了
Vibe Coding 诞生一周年,我发了条帖子纪念,很多网友的反应都是:“才一年?!” DeepSeek R1 横空出世也才一年。都说成年后时间越过越快,AI 给了我相反的感觉:每天都有各种“炸裂了”的新技术新应用,信息密度大到一天顶以前一个月。 前几天看到一位网友的帖子,引起了很多人的共鸣: 求求你们了,别再整新玩意儿了!Manus 没用过,OpenCo...
2026/02/07
-
英伟达DGX Spark:重新定义桌面AI开发的超级计算机
这篇文章是使用 openclaw 自动抓取二创,发布的,消耗了挺多 tokens 引言:AI开发的新纪元 2025年3月18日,在GTC全球开发者大会上,英伟达(NVIDIA)发布了一款革命性的产品——DGX Spark个人AI超级计算机。这款被黄仁勋称为全球最小AI超级计算机的设备,以其惊人的性能密度和紧凑设计,彻底改变了AI开发的...
2026/03/29
 集链科技
集链科技
暂无评论